
Hamel Husain & Shreya Shankar - AI Evals For Engineers & PMs
by Hamel Husain & Shreya Shankar
Course Proof
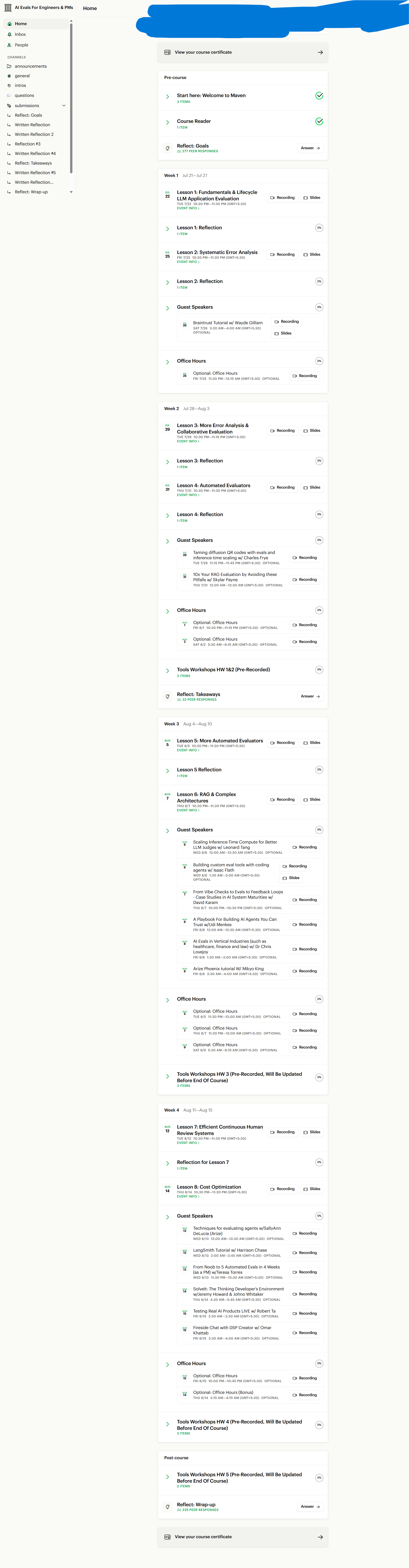
Course Details
AI products don’t fail because of bad models — they fail because teams don’t know whether they’re improving or breaking things. If you’re shipping AI features without rigorous evaluation, you’re guessing. This guide explores a structured approach to AI evaluations that helps engineers and product managers build measurable, reliable, and high-ROI AI systems.
Designed by experienced ML leaders like Hamel Husain and Shreya Shankar, this framework focuses on real-world AI evaluation strategies — not theory.
Why AI Evaluation Is the Missing Layer in Modern AI Development
Shipping AI isn’t the same as shipping traditional software.
You’re not validating deterministic outputs. You’re validating probabilistic systems where:
Outputs can be subjective
Prompt changes create unintended regressions
Performance varies across user segments
Metrics aren’t always obvious
Without structured evaluation pipelines, you risk:
Shipping broken prompt updates
Optimizing the wrong metrics
Wasting engineering effort
Failing silently in production
AI evaluation introduces systematic feedback loops — the backbone of continuous AI improvement.
What You’ll Learn: A Practical AI Evaluation Framework
1. How to Collect Data for Meaningful Evals
High-quality evaluation starts with high-quality data.
Instrumentation & Observability
You’ll learn how to:
Track model inputs and outputs
Monitor system behavior across features
Log failures and anomalies
Capture user interactions for feedback loops
Without observability, debugging AI systems becomes guesswork.
Synthetic Data Generation
No users yet? No problem.
Synthetic datasets help:
Discover edge cases early
Stress-test prompts and pipelines
Bootstrap early-stage AI products
Smart synthetic generation accelerates product-market fit by exposing weaknesses before customers do.
Choosing the Right Evaluation Tools
The eval ecosystem is crowded. You’ll understand:
When to use LLM-as-a-judge frameworks
How to compare vendors
What tooling aligns with your product stage
2. Error Analysis: The Fastest Path to Improvement
Most teams collect data but don’t analyze it deeply.
Error analysis helps you:
Identify systematic model failures
Cluster recurring error types
Detect regressions across experiments
Prioritize engineering effort
Instead of fixing random issues, you’ll focus on the highest-impact improvements.
Analyzing Agentic Systems (RAG & Tool Use)
Modern AI systems include:
Tool calls
Multi-step reasoning
Retrieval-Augmented Generation (RAG)
External APIs
Each component introduces failure points.
You’ll learn how to:
Diagnose retrieval relevance
Track hallucinations vs. grounding errors
Identify propagation failures in pipelines
3. Implement Effective Evaluations (Not Generic Ones)
Off-the-shelf evaluation templates don’t work for serious AI products.
You need:
Product-specific evaluation criteria
Stakeholder-aligned metrics
Domain-aware annotation guidelines
Designing Trustworthy Metrics
You’ll develop:
Custom evaluation rubrics
Scientific validation processes
Inter-annotator agreement standards
LLM-as-a-Judge & Code-Based Evals
Automated evaluation is powerful — but only if structured properly.
You’ll learn:
How to design robust judge prompts
How to validate judge consistency
How to combine human + automated review
Automation reduces cost, but rigor builds trust.
4. Architecture-Specific Evaluation Strategies
Different AI architectures require different evaluation approaches.
Evaluating RAG Systems
Key metrics include:
Retrieval relevance
Context grounding
Factual accuracy
Hallucination rate
Measuring the wrong metric can hide catastrophic issues.
Multi-Step Pipelines & Error Propagation
In multi-stage AI workflows:
Early mistakes amplify downstream
Root causes get buried
You’ll learn structured debugging frameworks that isolate failure sources quickly.
Multi-Modal Systems
Text, image, and audio interactions require:
Cross-modal evaluation strategies
Specialized annotation schemas
Domain-specific benchmarking
Generic evaluation doesn’t scale across modalities.
5. Running Evals in Production
Evaluation isn’t a one-time exercise. It’s an operational discipline.
CI/CD Evaluation Gates
Before deployment:
Run automated evaluation suites
Detect regressions early
Compare experiments consistently
AI systems should have the same deployment discipline as traditional software.
Dataset Management & Overfitting Prevention
Repeatedly testing on the same dataset creates overfitting risks.
You’ll learn:
Dataset versioning strategies
Holdout set management
Continuous refresh processes
Safety & Guardrails
Production AI requires:
Toxicity checks
Bias detection
Compliance safeguards
Safety metrics must be embedded — not bolted on.
6. Ensuring High ROI from AI Evaluations
Not every problem needs an evaluation framework.
One of the most overlooked skills in AI product development is knowing:
When to write an eval
When not to
Where engineering time creates leverage
Reducing Review Friction
Better UI for reviewers leads to:
Higher annotation quality
Faster turnaround
Better dataset scaling
Team Structure & Collaboration
AI eval success depends on:
Clear ownership
Defined responsibilities
Cross-functional alignment
Thoughtful automation
Without process discipline, evaluation becomes noise instead of signal.
Who This Is For
This framework is ideal for:
Machine Learning Engineers
AI Engineers
Product Managers
Applied AI Researchers
Startup Founders building AI products
If you’re asking questions like:
“How do I test subjective outputs?”
“Did my prompt change break something else?”
“What metrics should I track?”
“Can I automate evaluation safely?”
Then structured AI evaluation isn’t optional — it’s essential.
Final Takeaway: Stop Guessing. Start Measuring.
AI products don’t improve accidentally. They improve through systematic evaluation, disciplined experimentation, and rigorous feedback loops.
If you want to build AI systems that outperform competitors — not just demos that look impressive — you need evaluation frameworks embedded into your engineering culture.
AI evals aren’t overhead.
They’re the difference between experimentation and engineering.


